Request a
Business Customized Quotation
+886 2 8797 8337
12F-2, No.408, Ruiguang Rd., Neihu Dist., Taipei City 11492, Taiwan
Center of Innovative Incubator R819, No. 101, Section 2, Kuang-Fu Road, Hsinchu, Taiwan
ONNC Compiler
Born for AI-on-Chips
ONNC (https://onnc.ai) compiler is a bundle of C++ libraries and tools to boost your development of compiler for AI-on-chips. More than 90% system-on-chips designed for deep learning applications are heterogeneous multicore architectures. ONNC is designed for transform neural networks into diverse machine instructions of different processing elements, variant DMAs, hierarchical bus system, high-speed I/O and fragmented memory subsystem in such intricate system-on-chips.
Systems architecture of ONNC
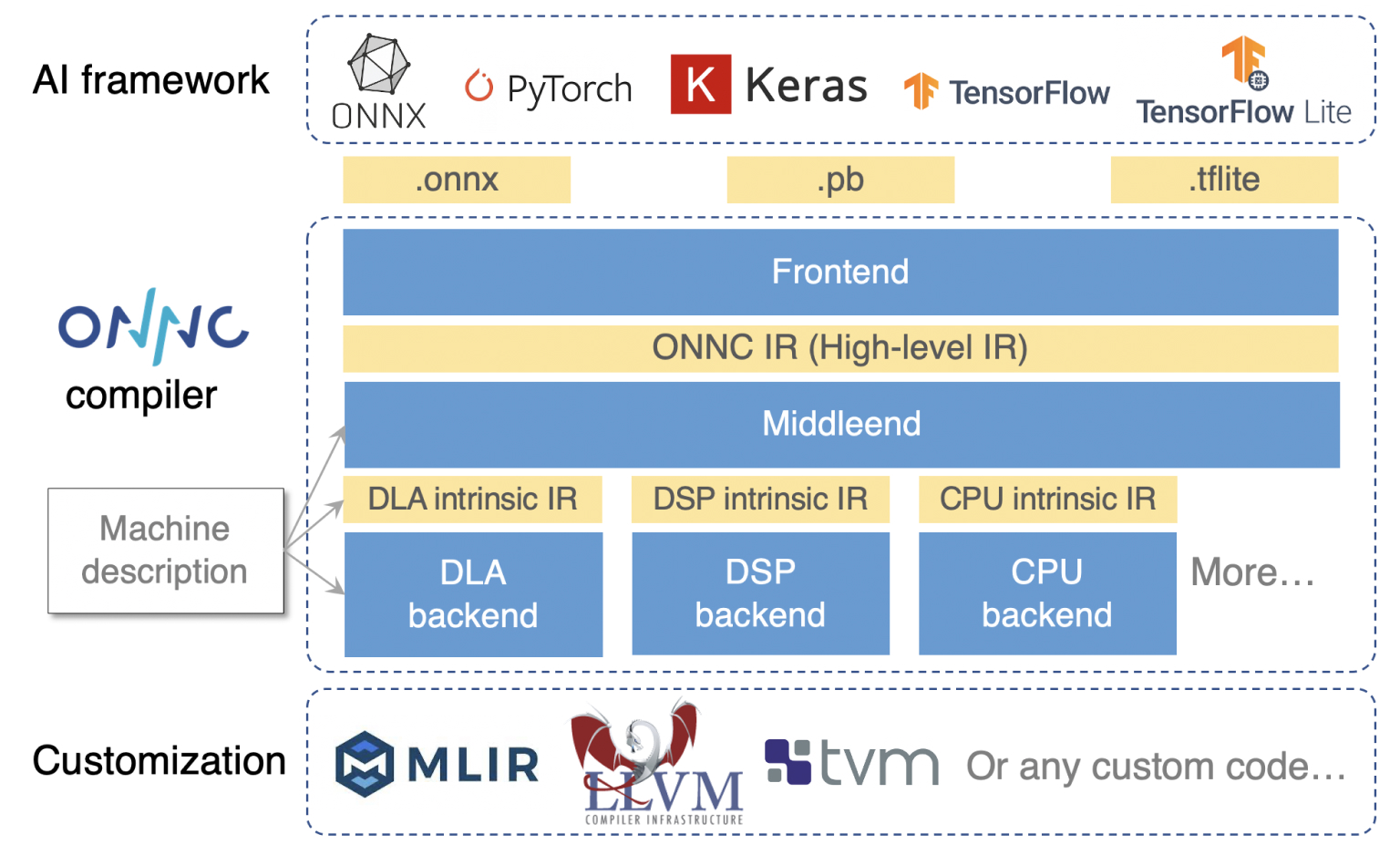
Connect to Famous Deep Learning Frameworks
ONNC compiler supports prominent deep learning frameworks, including PyTorch and Tensorflow. Its modular parser leverages MLIR frameworks to transform various file formats into its intermediate representations. TensorFlow, TensorFlw Lite, PyTorch, ONNX, and TVM Relay are first-class supported. ONNC compiler also has a Python-based pre-processor. The pre-processor uses machine learning algorithm to find out a best way to transform input files into supported formats.
| Framework | Support Class | Model Zoo |
|---|---|---|
| TensorFlow | Compiler Frontend | TF-Slim, Zurich AI Benchmark, MLPerf |
| TensorFlow Lite | Compiler Frontend | TF-Slim, Zurich AI Benchmark, MLPerf |
| PyTorch | Compiler Frontend | TorchVision |
| ONNX | Compiler Frontend | ONNX Module Zoo |
| TVM Relay | Compiler Frontend | |
| Keras H5 | Pre-processor Frontend | Keras Application |
Scale Up Deep Learning Tasks on Heterogeneous Multicore
AI SoCs have diverse programmable components. A typical AI SoC may has these programmable components:
CPUs with different configurations, like Big.Little ARM, multiple RISC-V or ARC,
DSPs to process input/output data
DMAs with different visibility
programmable video/audio encorder/decoder
customized deep learning accelerators
home-made synchronization mechanism for the other processing elements
For each programmable component, a compiler usually has a corresponding backend to generate machine instructions.
Single Backend Mode
ONNC compiler has various configurations to support different type of IC design groups. For deep learning accelerator IPs, such as Compute-In-Memory and Neural Processing Unit, ONNC compiler supports single backend mode and generates specific machine instructions. The single core can be a general-purpose CPU like RISC-V, a neural network accelerator library, such as CMSIS-NN, or domain specific accelerator like NVDLA.
C backend for general-purposed CPU, like X86, ARM, RISC-V and ARC
NNLib backend for neural network accelerator library, such as CMSIS-NN and Andes NNLib
Target backend for domain-specific accelerator, like NVDLA, DMAs, etc.
Multiple Backend Mode
For AI system-on-chip, like PCIe accelerator card and Smartphone Application Processor, ONNC compiler has multiple backend mode to coordinate all backends. A special component, ‘‘platform’’, reads a user configuration file and instantiates all the backends listed in the configuration file. The platform object manages all shared resources like DRAM and software locks of synchronization dashboard. Backends acts like a client of platform object to generate corresponding machine instruction stream in a common loadable file.
Support Multiple View Address Maps
Most intricate features in heterogeneous multicore system are the fragmented memory space and hierarchical bus system with complex DMA settings. Such systems have multiple master devices. Each master has different address maps of shared slave devices and different visibilities to access shared slave devices. Memory space in such system is rarely flat. It is often fragmented, even not linear. There are many address holes interleaving in the space. Some memory segments are addressed by multiple tags and must be accessed by some modulo mechanisms.
ONNC compiler uses register description language to model multiple view address maps. Registers in the language are not limited to conventional configuration registers, but can also refer to register array and memories. With the memory model, its unique memory allocation system can handle the non-linear and fragmented memory spaces. The allocation system projects the memory space into a high-dimension concave and uses its unique intermediate representation to find out the best memory allocation policy. In our practices, ONNC compiler saves 40%~60% RAM demand in most AI systems, including recommendation system, smartphone application processor and MCU-based system.
Enhance Performance through Hardware/Software Co-optimization
In many AI SoCs, the performance bottleneck is about moving data between storages and processing units. ONNC compiler uses several strategies to eliminate data movement overhead.
Software Pipelining
Neural network inference behaves like a data flow in a big loop. We leverage this feature and reorder all tasks in a pipeline. The basic idea of software pipelining is overlapping loop iterations and maximizes utilization of all processing elements. This technique is particularly effective for recommendation systems and some architectures like RISC-V mesh.
DMA Allocation
Number of DMAs is usually less than the number of processing units the DMA can see. ONNC compiler knows address views of each DMAs and has unique algorithm to resolve contention of DMA usages between different processing units at compilation time.
Bus/Port Allocation
Multiple processing units may access to the same storage at the same time. ONNC compiler uses interference graph to schedule all tasks on processing units and resolve all bus/port contentions at compilation time.
Memory Allocation
Several processing units may share small but high-speed SRAM tiles. When ONNC compiler find a datum is too big to put in the SRAM, it separates the big datum into small pieces and put them in the next level storage, like DRAM or Flash. It also schedules all the data movement to enlarge bus utilization and save peak memory usage.
ONNC Compiler Internals
Compiler flow commonly separates into three parts in order: frontend, middle-end, and backend. For a DLA compiler, the frontend is expected to support a rich set of model formats, and then make the parsed graph compact and explicit enough for ease of further optimization.
The middle-end is expected to partition a model graph into groups, each of which will be lowered into DLA, DSP, or CPU backend, that when working together, can achieve high performance in a heterogeneous system.
The backend is expected to perform hardware-dependent optimization of scheduling and resource allocation to maximize performance and minimize memory footprint.
ONNC compiler provides the frontend with the following features.
Parsing model files from popular AI frameworks of ONNX, PyTorch, TensorFlow, and etc.
Shape inference to resolve non-trivial tensor shapes in models.
Constant folding and redundancy removal to reduce model size.
Lowering into a so-called ONNC IR, which is a high-level IR composed of coarse-grained operators like convolution and pooling.
As for the middleend, ONNC compiler provides the following features.
Partitioning for heterogeneous computing.
Off-the-shelf CPU fallback mechanism for popular CPUs like ARM and RISC-V.
Operator tiling to fit DLA design constraints.
As for the backend, ONNC compiler provides the following features.
we abstracted the hardware architecture into a set of pre-defined configurations, like memory size, bus address alignment, functions involved in the pipeline, and so on. We formalized those configurations into an easy-to-learn, so-called machine description language. Then we developed corresponding hardware-dependent algorithms. This way you can easily take advantage of the off-the-shelf hardware-dependent optimizations from ONNC compiler.
Some key optimizations are provided as below.
Software pipelining.
Scheduling for multiple resources.
DMA operator insertion.
Memory allocation supporting multi-level hierarchy.
Bus allocation.
In conclusion, ONNC compiler is
Modularized for easy integration with your own compiler in the way you need
Retargetable for satisfying many different hardware architectures’ need
Optimized in terms of performance and resource utilization.