Request a
Business Customized Quotation
+886 2 8797 8337
12F-2, No.408, Ruiguang Rd., Neihu Dist., Taipei City 11492, Taiwan
Center of Innovative Incubator R819, No. 101, Section 2, Kuang-Fu Road, Hsinchu, Taiwan
Forest Runtime

Forest Runtime executes compiled neural network models on the hardware platform of your choice. It provides common C++ APIs with C and Python bindings for various AI application doing inference. Forest Runtime is ‘’‘retargetable’’’. It has modular architecture and we’ve ported it on diverse hardware platforms, including ‘‘datacenter’’, ‘‘mobile’’ and ‘‘TinyML’’. Forest Runtime supports ‘’‘modern neural network models’’’. With ‘‘hot batching’’ technology, Forest Runtime supports the models that needs to change batching and input shapes at runtime, such as ‘‘DLRM’’, ‘‘transformer’’ and ‘‘BERT’’. Forest Runtime is ‘’‘scalable’’’. It automatically fuses multiple models into a single one for saving the CPU/NPU synchronization overhead. Its unique ‘‘bridging’’ technology allows multiple applications using a common accelerator card and coordinates tasks among multiple accelerator cards in a single server.
Retargetable
Systems architecture of Forest Runtime
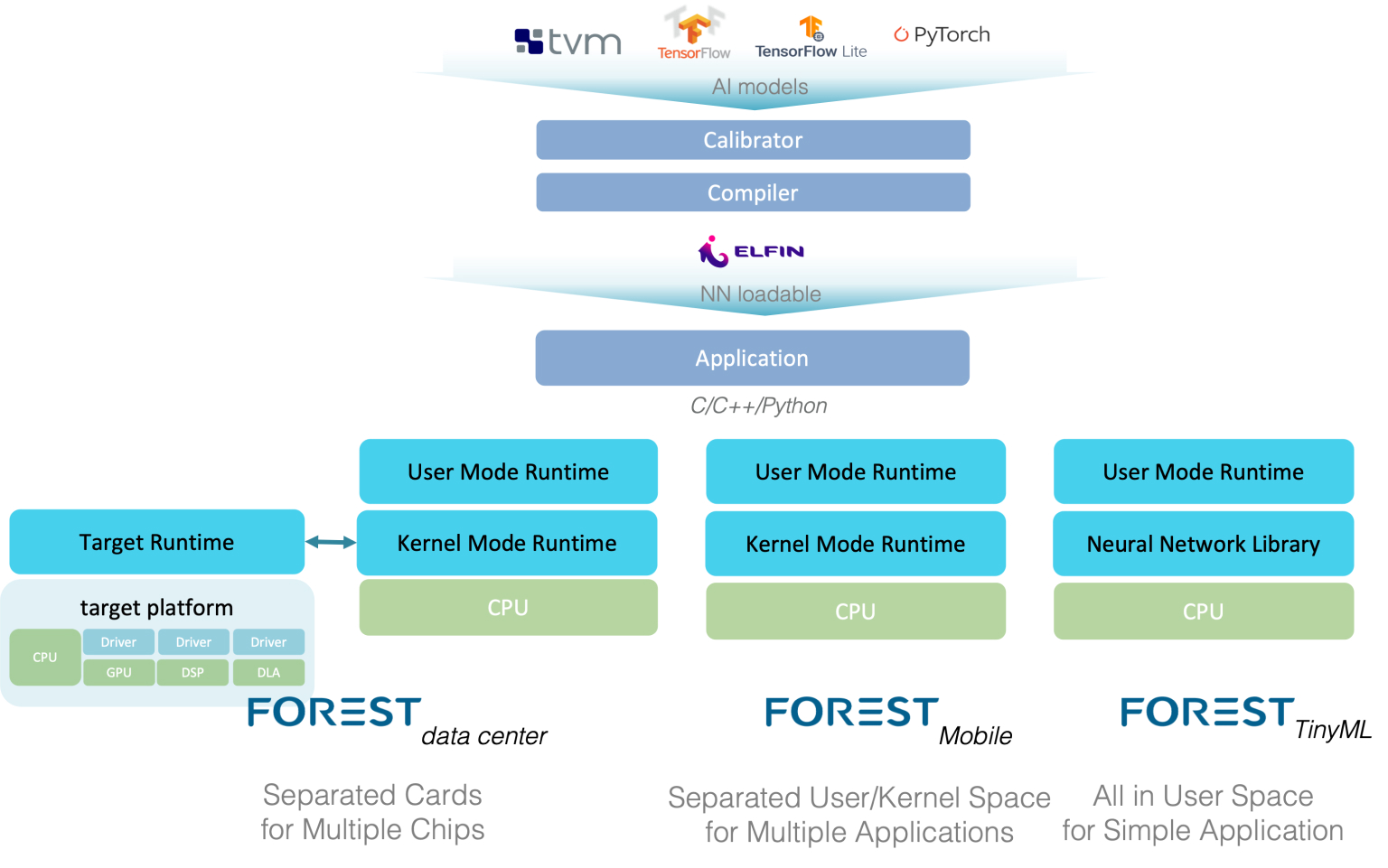
Forest Runtime is ‘‘modular’’ and ‘‘easy to reconfigure’’ to the hardware platform of your choice. It has three modules: user mode runtime, kernel mode runtime and target runtime. User mode runtime provides common APIs to applications. For the applications running on simple micro-controller or smartphone, it has ‘‘synchronous’’ inference pipeline to minimize the response-time of the hardware platform. For some data center applications, for example recommendation system, the user mode runtime provides ‘‘asynchronous’’ inference pipeline to maximize the throughput.
Smartphones and mobile devices need to run multiple AI Apps on a single engine. In this case, the kernel mode runtime manages the hardware, software resources for all user mode runtime threads which accessing the same hardware.
On the other hand, applications in a data center must exploit all hardware resources from servers. Modern accelerator cards for cloud inference are heterogeneous multicore system-on-chips which connects to the host by high speed links like PCIe and CXL. The target runtime is designed for such heterogenous multicore system. It dispatches tasks from kernel to diverse processing elements by compiler’s instructions and builds the software pipeline between these processing elements to maximize the throughputs.
Support Modern Neural Network Models
Forest runtime allows neural network applications arbitrarily change model batch size and input share size at runtime. This feature is very useful for data center applications to fully utilize the hardware throughput and minimize the response time.
It is useful because modern neural networks usually keep input shapes and batch size unknown until deployment. Modern neural networks often arbitrarily change tensor shape at runtime. Most models, such as YOLOv4 and DLRM, their different input batches may have different number of samples, and the input shapes in different batches are different.
Many hardware platforms ask extra revision on networks to fix input shape and batch size for fitting hardware limits which has scarification on application flexibility and throughput. Forest Runtime uses ‘‘hot batching’’ technology, to modify the batch sizes and input shape at runtime. Unlike just-in-time compilation or ahead-of-time compilation, ‘‘hot batching’’ doesn’t invoke compiler transformation at runtime. Instead, it uses linker technology to change the model binary directly. This approach is x10 faster than the other compiler-based technologies.
Scalable
Forest Runtime supports several ways to scale your application.
Model fusion
Forest Runtime has a dynamic linker. The linker can fuse multiple models into single one just like symbol resolution in traditional linker. Fused models have less synchronization overhead of CPU and NPU.
Application Context Switching
Forest Runtime behaves like an operating system on AI related hardware, software resources. It manages a contiguous memory space in kernel for all applications using the same chip. When an application is swapped out the schedule, it saves necessary feature maps and data in the pipeline into the backed memory system.
Streaming Multiple Accelerator Card
Data center system or mobile system have multiple neural network engines in a single system-on-chip. Take smart surveillance for example, such system usually have more than ten programmable processing elements, like vector engines, home-made DSP, big-little CPUs and DMAs. Forest Runtime chains all processing elements in a pipeline and pipes all inference tasks in a stream by compiler instructions and fully utilize all hardware resources in a server.
Conclusion
Forest Runtime is designed for heterogenous multicore system-on-chips. It provides common C++/C/Python API to different applications of data center, mobile and TinyML. It’s retargetable. Its modular design makes it is easy to port kernel mode runtime and target runtime on variant hardware platforms. Its ‘‘hot batching’’ techniques support modern neural networks including BERT, Transformer and DLRM which must arbitrarily change input share and batch size at runtime. It’s scalable. It uses model fusion, context switching and software pipelining to support multiple models, multiple applications and multiple accelerator cards in one system.