Request a
Business Customized Quotation
+886 2 8797 8337
12F-2, No.408, Ruiguang Rd., Neihu Dist., Taipei City 11492, Taiwan
Center of Innovative Incubator R819, No. 101, Section 2, Kuang-Fu Road, Hsinchu, Taiwan
ONNC Calibrator
Born for AI-on-Chips
ONNC Calibrator leverages hardware architecture information to keep AI System-on-Chips in high precision through the post-training quantization (PTQ) technique. The key indicator to validate a quantization technique is its precision drop. ONNC Calibrator provides architecture-aware quantization that helps AI chips maintain 99.99% accuracy of precision even in fixed-point architecture such as INT8. Further, ONNC Calibrator is designed for heterogeneous multicore devices. It supports these key features:
Configurable for variant bit-width architectures (e.g., INT1, INT4, and INT8)
Supports multiple engines with bit-width datapaths that are different in a single architecture
Built-in rich entropy calculating policies, such as max, KLD, L1, and L2
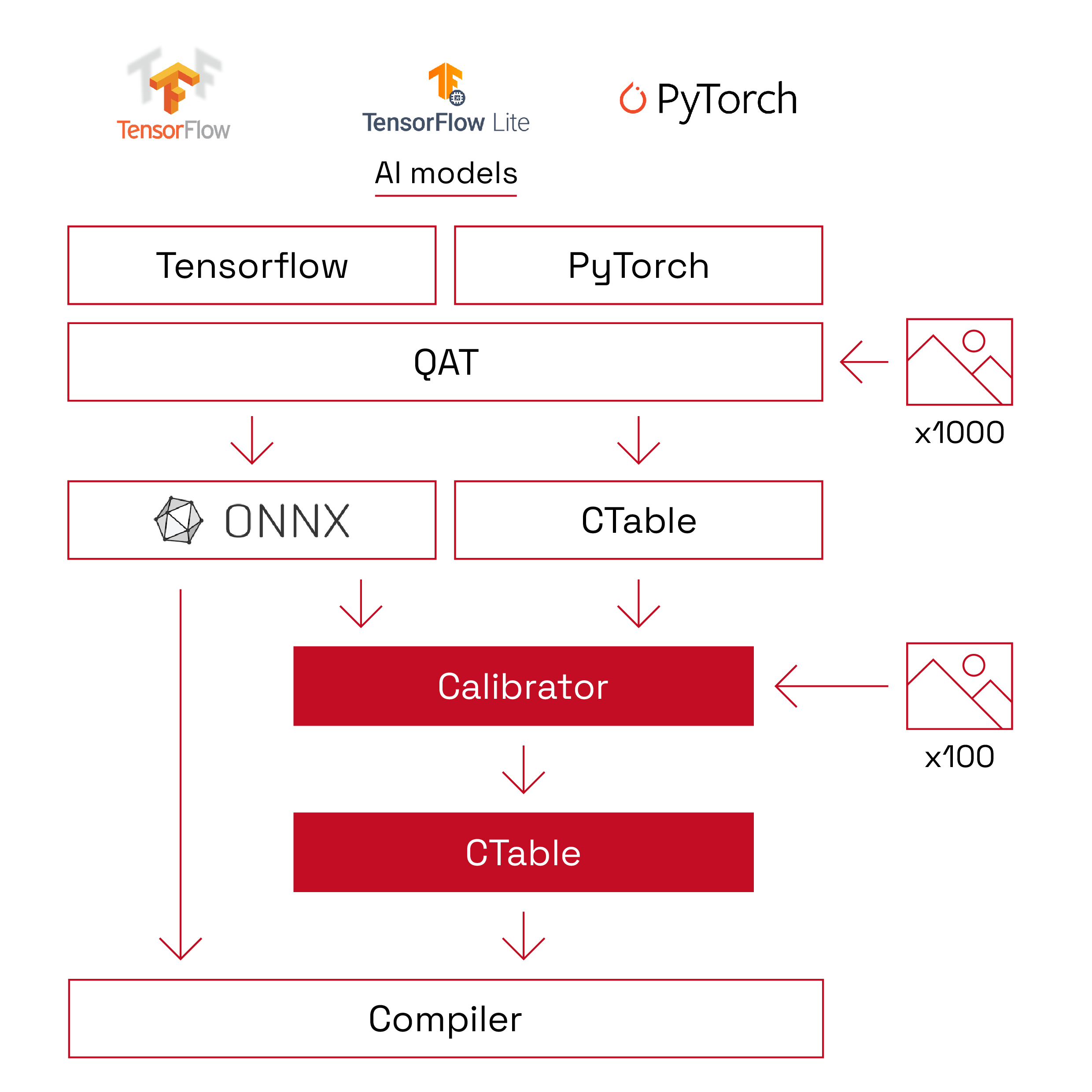
Calibration Workflow Overview
ONNC Calibration uses the architecture-aware post-training quantization (PTQ) technique. Unlike re-training technologies, PTQ is “safe,” meaning that it does not change the topology and semantics of neural networks. It reads 300-500 input samples to determine the profile of the input value distribution. Additionally, the output is a table (i.e., CTable), which contains quantization parameters to help the compiler adjust the precision in every layer. Neural network models are not changed after quantization. ONNC Calibrator knows the hardware of your choice and adds control information in the produced CTable. ONNC Compiler will then follow up on the information and use this control information to maintain precision and accuracy.
Compared with re-training technology such as QAT, the ONNC Calibrator is “fast.” PTQ technology does not require back propagation to re-train neural networks. Instead, it uses the profile of input value to determine the best scaling factor of each network layer. The quantization time depends on the speed of inference, not training. It usually takes only a few seconds for standard computer vision models. For some large models, such as DLRM 100G, it only takes several minutes.
ONNC Calibrator has “good interoperability.” ONNC Calibrator uses the ONNC compiler front-end, which can read most neural network model formats, including ONNX, PyTorch?, TensorFlow?, and TensorFlow? Lite. Furthermore, ONNC Calibrator coordinates well with quantization-aware training (QAT) scripts of these frameworks. It can read the CTable generated by QAT scripts and refine the CTable with hardware information.
One unique feature of the ONNC Calibrator is its “architecture-aware quantization.” ONNC Calibrator has a built-in precision simulator to emulate all precision-change points in a data path. ONNC Calibrator uses hardware control registers as extended storage of quantization information. With the hardware information, ONNC Calibrator can achieve high precision of the hardware. In most well-defined microarchitectures, the precision drops of computer vision models are less than 1%. In DLRM cases, its precision drop is less than 0.1%.
The overall workflow is shown in the chart below.
Internal Quantization Technologies
ONNC Calibrator is versatile for quantization. Similar to the ONNC Compiler, it is retargetable and can support multiple heterogeneous hardware engines of one chip. It also has many built-in algorithms to calculate scaling factors for each layer. The most powerful feature is that it has an internal AI engine to determine the best algorithm combination of scaling-factor calculation.
| datapath bit-width | variant bit-width, int1, int4, int8, etc. |
| multiple engine support | mixed precision on different engines |
| approach | post training quantization |
| multiple policies | max/KLD/L1/L2 |
| mixed policies | grid search for different policy |
| deliverables | as a standalone tool, a compiler optimization pass, or a library |
Conclusion
ONNC Calibrator is equipped with architecture-aware algorithms to quantize and compress a deep learning model while maintaining high accuracy.
ONNC Calibrator is designed for adapting various hardware architectures, including CIM and analog computing.
ONNC Calibrator can be delivered in flexible forms, including a standalone application, compiler optimization pass, or library.