Request a
Business Customized Quotation
+886 2 8797 8337
12F-2, No.408, Ruiguang Rd., Neihu Dist., Taipei City 11492, Taiwan
Center of Innovative Incubator R819, No. 101, Section 2, Kuang-Fu Road, Hsinchu, Taiwan
Smart TV

About_
Super Resolution under FPS Constrainsr
As the demand for bigger Smart TV increases, so does the need for higher resolution videos. Super Resolution is one of the key AI features equipped with Smart TV and improves the quality of videos. Deep learning models, such as EDVR and VSR-DUF, enhance video quality on a large scale. However, the biggest challenge for adopting these models on SmartTVs is the frame rate. Frame rate, which is expressed Frames Per Second (FPS), is a key metric to evaluate performance of inference. According to studies, 95% inference time are in data traffic when running a deep learning model, instead of executing instructions. ONNC optimizes data movement by HW/SW co-design technology and archives 4.8x speed-up.
95% of Inference Time is Spent on Data Movement
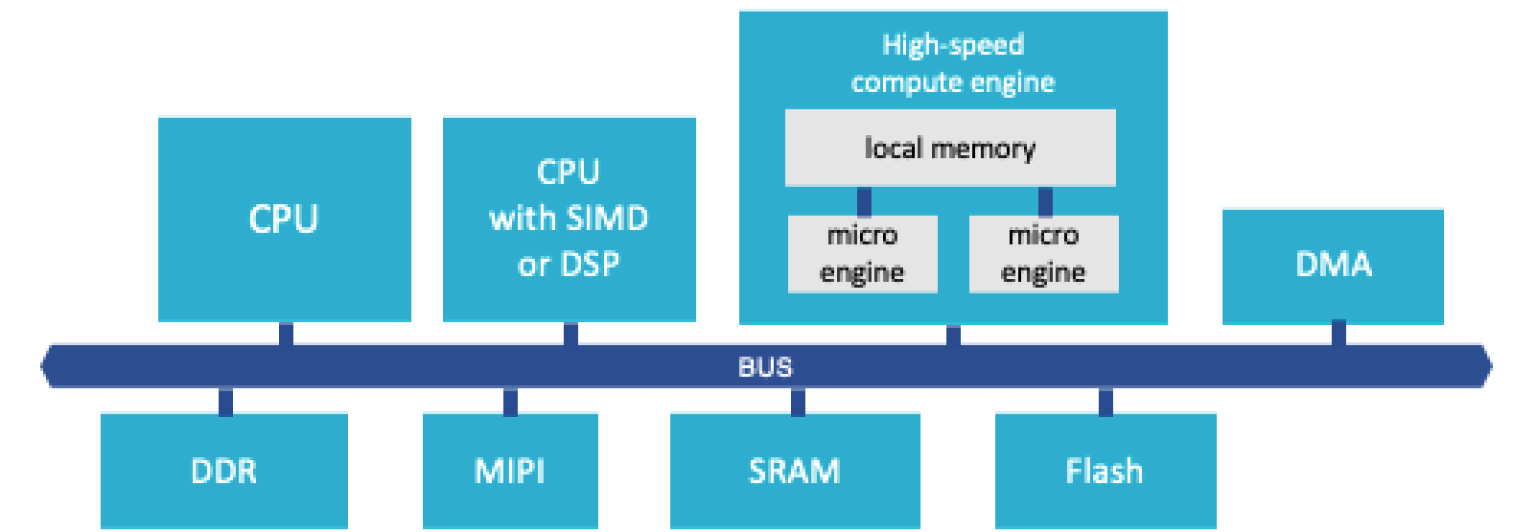
Both video quality and frame rate are important factors to consider when selecting a SmartTV. Deep learning based Super Resolution models can greatly improve video quality, but they may reduce frame rate. In order to increase frame rate, we need to improve hardware utilization of AI chips that are running deep learning models in SmartTV. However, even if an AI chip supports all operators inside a neural network, its hardware utilization is usually less than 5%. According to our studies, 95% of inference time is in data traffic among Processing Elements(PEs) and memory storage. The data traffic comes from:
Compulsory data movement
Move weights, bias, inputs and outputs from the other storage to DLA
Unessential data movement
Data spill out from a small local storage to large external storage, especially for feature maps
Unessential execution
CPU, DSP and DLA spend time for data coherency or find the next operators to run
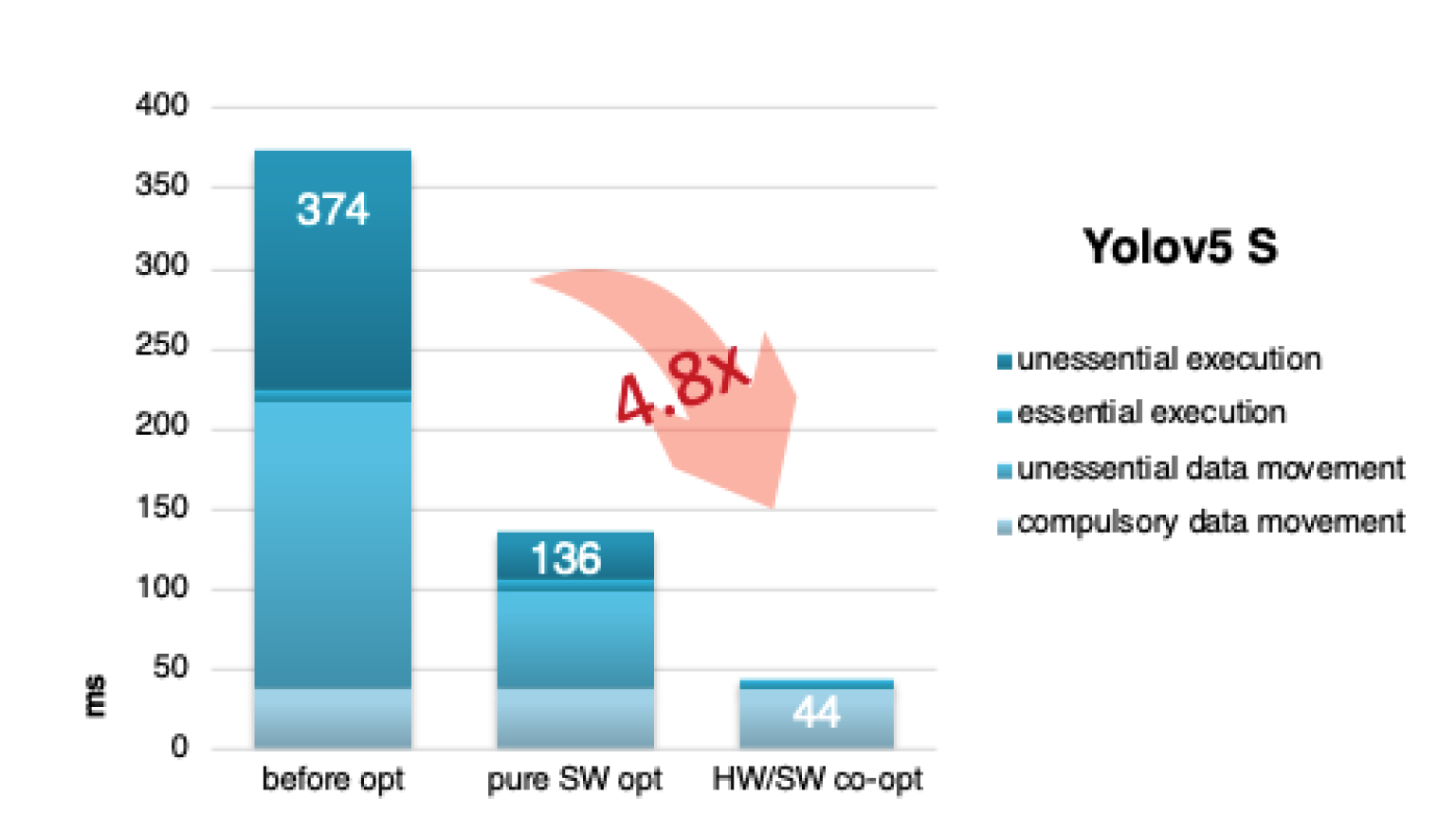
ONNC Archives 4.8x Speed-up by Data Movement Optimization
ONNC eliminates unessential data movement and execution and speed inference up by 4.8 times. These achievements are contributed by below unique technologies:
Skymizer Neural Network Interference Graph® technology analyzes the model and eliminates the number of capacity misses and coherency misses of the traffic
Skymizer Fire-and-Forget® service optimizes DMA and CPU interrupt design. By this HW/SW co-design technology, ONNC runtime can eliminate the number of CPU-DLA-memory interactions
Achievement_
ONNC Enhances AI Chip's Competitiveness by Boosting Performance
Throughput and latency are two important factors that determine an AI chip's product competitiveness. ONNC helps AI chip providers improve the performance of inference by optimizing data movement and archive 4.8x speed-up. Besides, ONNC provides advanced algorithms to improve performance, including software pipelining, scheduling for multiple resources, DMA operator insertion, etc. ONNC Calibrator is also a powerful tool to speed up the performance of a neural network, without sacrificing precision. Talk with our experts and learn how ONNC helps you build competitive AI chips.