Request a
Business Customized Quotation
+886 2 8797 8337
12F-2, No.408, Ruiguang Rd., Neihu Dist., Taipei City 11492, Taiwan
Center of Innovative Incubator R819, No. 101, Section 2, Kuang-Fu Road, Hsinchu, Taiwan
AIoT

About_
Running Deep Learning Models in Resource-Restricted IoT Devices
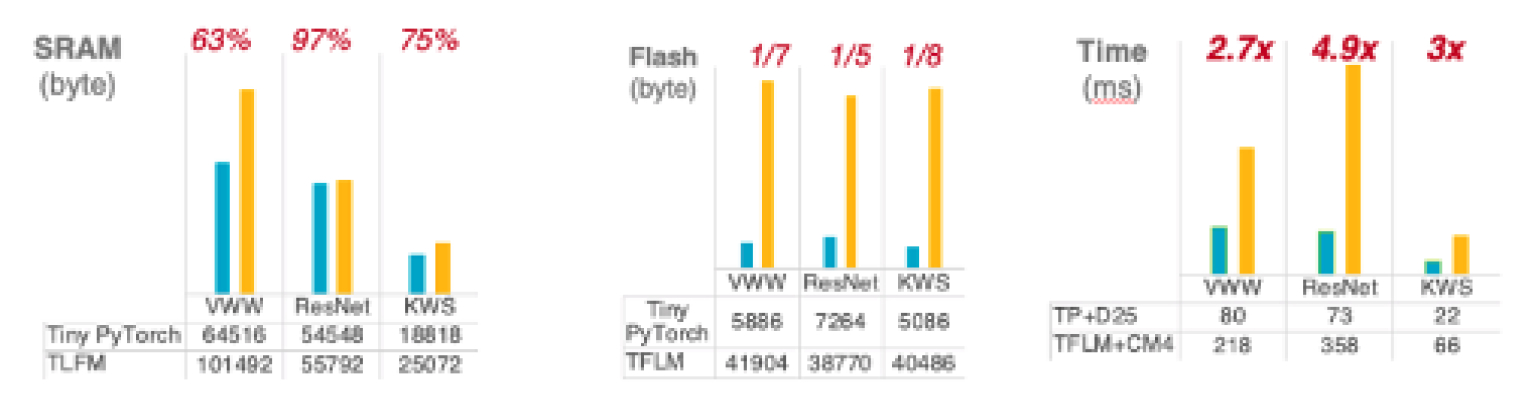
IoT devices are becoming increasingly popular due to their convenience and portability. By equipping these devices with AI, we can increase their value and enable them to perform tasks that were previously impossible. For example, AI-equipped IoT devices can be used to create smart houses that can automatically adjust the temperature and lighting to suit the occupants. Deep learning is a state-of-the-art algorithm in AI realm. However, it is computation-intensive. Running deep learning on IoT devices is a great challenge due to the limitation of computational power and memory. ONNC can optimize deep learning models for TinyML tasks and reduces 63% of SRAM usage and speeds up 490% of inference time.
Challenges for Running AI on IoT Devices
Deep learning is a state-of-the-art algorithm that is used in machine learning, which is a subcategory of Artificial Intelligence(AI). It is capable of learning complex patterns in data and making predictions based on those patterns. Deep learning can help to improve the accuracy of predictions and classification. It has been shown to be effective in a variety of tasks, such as image recognition, anomaly detection, voice triggering, etc.
However, One of the great challenges in implementing deep learning on IoT devices is the resource restrictions placed on these devices. IoT devices are often very limited in terms of their computational power and memory, making it difficult to run complex deep learning algorithms on them. In addition, many IoT devices are also battery-powered, so power consumption is another important consideration.
This challenge becomes harsher on microcontroller units (MCUs), one of the major computing units in IoT devices. MCUs are often used to control various peripherals and devices. They have been broadly used in almost every field of electronic devices due to their advantage in cost.

ONNC Supports Running AI on ARM Cortex-M and Andes MCUs
ONNC supports backends for both ARM Cortex-M and Andes MCUs. ONNC Compiler optimizes computation graphs in TinyML Models and compiles the models into C++ code. Embedded engineers can use the C++ code generated by ONNC as a library and integrate it in their IoT application. Comparing with other solutions for running AI models on MCUs, ONNC's method does not rely on runtime thus can greatly save memory and storage footprints. In our experiments, such approach reduces 63% of SRAM usage and 87.5% of Flash usage.
From the perspectives of performance, besides the optimization techniques applied on the Deep Learning models, ONNC Compiler leverages CMSIS-NN(for CortexM) and libNN(for Andes) to unleash the potential power of MCUs. Both ARM Cortex-M and Andes MCU require Deep Learning models to be run under INT8 mode. ONNC Calibrator, which is a Post-Training Quantization(PTQ) tool, can convert a FP32 model into INT8 mode to reduce memory footprint and improve response time yet maintain high accuracy. In our experiments, ONNC speeds up inference time by 490%. The Accuracy remains 99% after FP32-to-INT8 quantization.
To sum up, ONNC's achievements in TinyML are:
ONNC reduces 63% of SRAM usage.
ONNC reduces 87.5% of Flash usage.
ONNC speeds up inference time by 490%.
Accuracy drop (from FP32 to INT8) is less than 1%.
Achievement_
ONNC helps IoT IC Providers Strengthen Product Competitiveness
Running deep learning on IoT devices is a great challenge. However, the benefits of doing so are significant. Deep learning can help to improve the accuracy of predictions and classification, and can reduce the amount of data that needs to be transmitted to the cloud for processing.
With ONNC's help, IoT chip providers can add Deep Learning supports for their existing IC chips and strengthen product competitiveness. Besides, ONNC also helps shorten time-to-market for new AI Chips by its full-fledged system software toolchain. ONNC toolchain contains Compiler, Calibrator, Runtime and Virtual Platform. Contact our experts today and learn more details!